Fake News e Pesce d’Aprile
Si, oggi è il primo aprile (April Fool) e come da tradizione si attaccano i pesciolini di carta sulla spalla dei propri amici inconsapevoli, e si ritorna a casa convinti di non essere stati colpiti da nessuno scherzo sino a quando qualcuno non ti chiede: “Ehi, cos’è quel pezzo di carta che hai appeso sulle chiappe con scritto ‘Sono un Idiota’ ”?
O per lo meno, così funzionava dalle mie parti nell’epoca pre-social.

Ora le cose sono cambiate. Siamo iper-connessi ed è più facile incontrarsi virtualmente piuttosto che fisicamente.
Ho dunque pensato ad un pesce d’aprile “social” che per me ha la valenza di un esperimento sociale.
Alcuni mesi fa, ho modificato la mia data di nascita impostandola sul 1° Aprile ed assicurandomi che fosse visibile ai miei contatti.
Ho utilizzato solo Facebook, anche se avrei potuto estendere lo scherzo a LinkedIn, Twitter, Gmail o altri servizi che potrebbero esporre la mia data di nascita. Sul perché ho utilizzato solo Facebook ci tornerò dopo.
Premetto che fa piacere ricevere gli auguri. Alcuni amici hanno visto la notifica su FB, ma mi hanno poi scritto su WhatsApp che è un mezzo più diretto e secondo me anche più emozionale (GRAZIE A TUTTI PER IL PENSIERO – Ora potete anche maledirmi ).
Chiedo scusa, se qualcuno si è sentito preso in giro, ma…ehi, è il primo Aprile 😛 !!!
Alcune considerazioni:
- Siamo spesso presi dal susseguirsi degli impegni e degli eventi e questo ci porta a dover accettare alcune cose come un dato di fatto. La criticità dell’informazione può essere pesata in vari modi a seconda della tipologia, del momento emotivo in cui la si “assorbe” e dal posto nel quale ci si trova. Non sempre si sente l’obbligo di verificare. Ma se non verifico 5 notizie sullo stesso tema che sono false, mi ritrovo poi ad avere un’idea distorta di quella che è la realtà su quel determinato tema.
- Immagino che qualcuno abbia anche dato per scontato il fatto che se la “notizia” è pubblica, ed è presa direttamente dai dati che IO ho inserito al momento dell’iscrizione su Facebook, allora è vera (in questo caso io e Facebook veniamo considerati delle fonti attendibile per i miei dati indipendentemente da quello che scrivo?)
In realtà, come in tutti i casi relativi alle informazioni che vengono pubblicate sarebbe bastato un minimo di giudizio critico per capire che era una fake:
1) Era il primo anno che la mia data di nascita era pubblica su Facebook (e sono iscritto al social network da molti anni). La domanda che ci si sarebbe potuto porre è: “Ma anche lo scorso anno gli avevo fatto gli auguri?”
– Molte delle persone che sono in contatto con me su Facebook lo sono anche su altri canali social. Un confronto avrebbe fatto emergere qualche dubbio
– A Settembre avevo fatto un post dove raccontavo che mi avevano fatto buttare da un aereo per celebrare il mio 40° compleanno
Mi sorprende anche il fatto che questo pesce d’Aprile così semplice da implementare, non sia poi così diffuso. Guardando i dati di registrazione e di variazione delle date di nascita, Facebook dovrebbe essere in grado di prevenire simili cose. Come ha detto recentemente Mark Zuckerberg, c’è ancora molto da fare e servono delle regolamentazioni adeguati che forzino le piattaforme a fare di più.
Nel mio caso, è chiaro che la Fake News non è nulla di fondamentale, ma la stessa logica si applica a tutto ciò che leggiamo\assorbiamo ogni giorno.
Il senso critico è importante e farsi delle domande lo è ancora di più. Sono sicuro che il 99% dei miei contatti Facebook applica un filtro a ciò che legge e che reputa fondamentale verificare, ma dobbiamo sempre ricordarci di non prendere le informazioni sottogamba indipendentemente da quanto poco importanti possano apparire.
p.s. Ora sto aspettando 1) che la mia bacheca di Facebook si popoli di insulti e 2) il primo aprile 2020 per ricevere nuovamente gli auguri
BUON PESCE D’APRILE a tutti e ocio alle Fake News
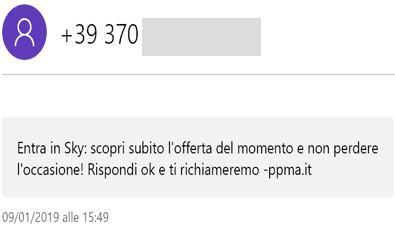
SMS indesiderati da -ppma.it e come difendersi (Parte 1)
SMS: OFFERTA del giorno “Un marziano gratis a casa tua”
Avete mai ricevuto un SMS da una società non autorizzata (come -ppma.it) che vi propone qualcosa di cui davvero non avete bisogno o completamente disconnesso dal vostro modo di vivere?
Ora, premetto che dal 2002 vivo senza un TV in casa. Si, sono uno dei pochi estremisti in questo senso ma vi garantisco che anche la mia compagna e mia figlia hanno accettato la situazione e…questa è un’altra storia. Quello che però mi preme far presente, è che non ho una TV e che qualsiasi offerta promozionale connessa al mezzo è per me irrilevante.
Da circa 4 mesi, continuo a ricevere SMS che promuovono iniziative di Sky sul mio numero di telefono che non ho mai condiviso e mi bado bene dal farlo, ogni qual volta devo dare il consenso per fini Marketing\Informativi o come vogliono chiamarli (sia online che nei moduli cartacei – sono uno di quelli che si legge le clausole).
Ho notato che gli SMS arrivano da -ppma.it e che esiste un sito dove viene chiesto di inserire il proprio indirizzo e-mail per essere cancellato http://privacy-mobile-advertising.it/
- Il sito mi pare abbastanza losco (visto che l’home page del dominio punta ad un semplice box dove inserire il proprio indirizzo e-mail)
- Non ho mai condiviso il mio numero con ppma e sono molto attento a dare i consensi. Vorrei capire come fanno ad averlo e da quale fonte l’hanno eventualmente acquisito
- PPMA in realtà sta promuovendo un servizio Sky. Mi sorge il dubbio che:
- PPMA stia sfruttando il nome di SKY per truffare le persone
- Sky stia sfruttando PPMA per attrarre nuovi clienti
Ad ogni modo, sia A che B sono due operazioni illecite.
Ho così pensato bene di non inserire il mio numero di telefono nel form disponibile sulla pagina e di fare una segnalazione alla polizia postale.
Dopo essermi registrato, ho navigato il sito https://www.commissariatodips.it (che pare essere fatto con logiche di Web 1.0) e sono finito su questa pagina dove in realtà, nel menù non ho trovato delle opzioni che facevano al caso mio ed ho inoltre trovato difficile per l’utente medio capire la tassonomia di ogni singola tipologia di reato.
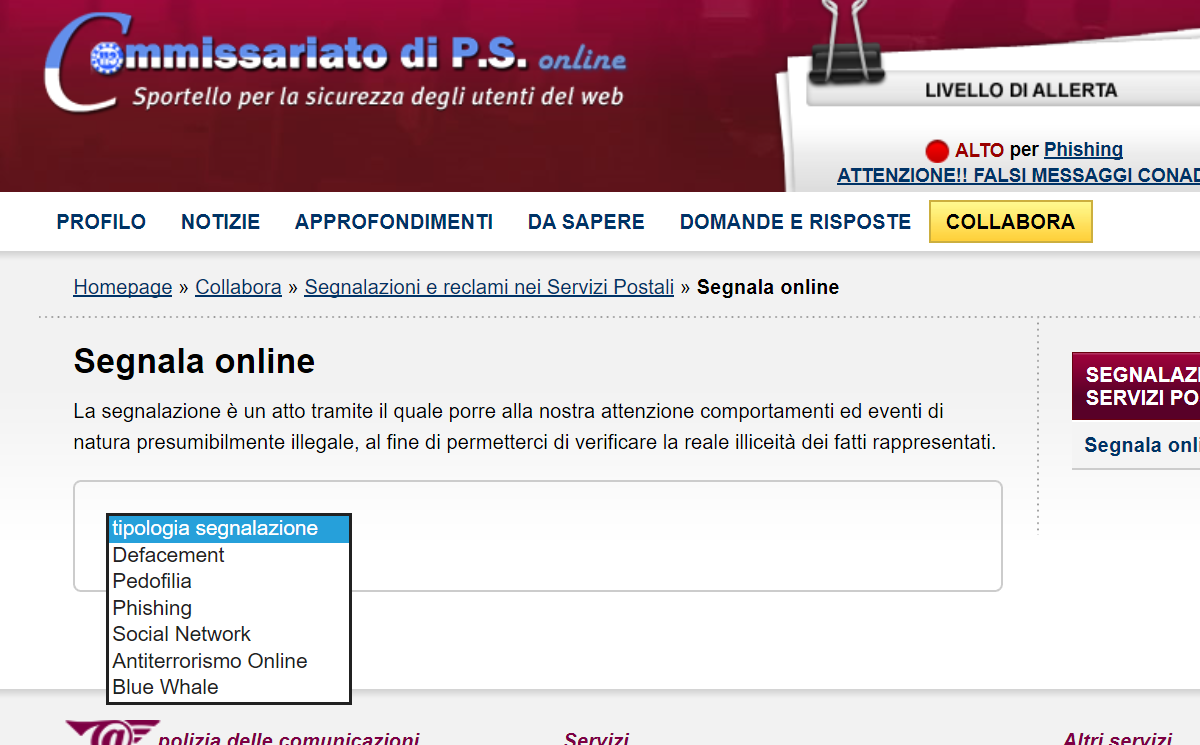
Se termini come Pedofilia e Antiterrorismo sono di uso comune, altri come Blue Whale, Defacement, Phishing e magari anche Social Network richiedono una breve descrizione o addirittura una tassonomia diversa (se avete dubbi a piè pagina trovate le definizioni). Forse avere un menù guidato aiuterebbe di più il cittadino medio che non sa cosa sia un motore di ricerca anche se lo usa tutti i giorni.
Anzi, mi viene in mente che sempre più utenti hanno il loro primo contatto con Internet tramite uno Smart Phone e sarebbe forse opportuno forzare il sistema imponendo che su tutti i telefonini venduti a cittadini Italiani (e non) nel territorio italiano con accesso ad Internet, venga pre-installata di default un’app (ufficiale della polizia postale) che permetta tale segnalazioni in modo veloce ed intuitivo. Una specie di “SOS APP”.
Sono stato così costretto ad utilizzare un altro form: https://www.commissariatodips.it/collabora/segnalazioni-e-reclami-nei-servizi-postali/segnala-online.html
Una volta inserito il mio testo, ho prontamente ricevuto una mail nella quale mi si confermava che la segnalazione era andata a buon fine ma:
- Sul sito ho dovuto cercare accuratamente per capire se la richiesta era andata a buon fine o meno perché il messaggio non viene accuratamente evidenziato (il giallo dell’immagine qui sotto l’ho messo io)
- Non vi è un numero di protocollo o di riferimento della pratica
- Dal sito non mi viene detto cosa succederà dopo aver effettuato la segnalazione e la mail contiene una serie di elementi che vengono valutati dai filtri antispam come elementi negativi, con il rischio che la stessa finisca nella cartella della posta indesiderata in quanto ha:
- Dei caratteri che non vengono accuratamente codificati
- Tre volte il link allo stesso sito in poche righe
- Due punti esclamativi consecutivi nella stessa frase anteceduti da uno spazio
- …

Sono ora in attesa da parte della polizia Postale per capire come verrà gestita la mia pratica, chi è la società che ha il mio numero di telefono e come lo hanno ottenuto e come possono aiutare me e le altre persone bombardate di SMS. Inoltre, non mancherò di segnalare come migliorare l’esperienza online e proporre la SOS APP . Vi aggiornerò in un nuovo post non appena possibile (PARTE 2)
Non contento, ho inoltre seguito il motto: “Aiutati che il ciel ti aiuta” e sono andato anche a guardare su https://who.is/whois/privacy-mobile-advertising.it chi ha registrato il sito e vedo che si tratta di una società che in realtà ha un sito internet diverso da quello sopra citato: https://www.rdcom.it/.
Visitando il sito vedo che compare il logo delle Autorità per le garanzie nelle comunicazioni AGCOM. Interessante…

Beh, a questo punto non ho potuto fare altro che porre la domanda numero 2 (“Non ho mai condiviso il mio numero con PPMA e sono molto attento a dare i consensi. Vorrei capire come fanno ad averlo e da quale fonte l’hanno eventualmente acquisito”) ai diretti interessati.
Ho così mandato una mail all’indirizzo che ho travato sul sito. Mi auguro che:
- Vi sia una soluzione rapida per tutte le persone che ricevono SMS da PPMA (che provvederò a condividere)
- La polizia postale migliori le modalità di accesso e di fruizione dei propri servizi per i cittadini
Fornirò un aggiornamento per tutti coloro che hanno volontariamente deciso di non essere più interessati ad avere dei Marziani gratis a casa (PARTE 2)
______________________
Definizioni prese da Wikipedia & altre fonti Web
– Blue Whale (“…si tratta di una sorta di percorso che un ragazzo può compiere assieme al proprio “curatore” attraverso una lunga serie di tappe progressive. Il percorso ha una fine nota e predeterminata: il suicidio”)
– Defacement (“Operazione di pirateria informatica consistente nella modifica del contenuto di una pagina o di un sito web mediante l’introduzione illecita di testi critici o sarcastici”)
– Phishing (“…è un tipo di truffa effettuata su Internet attraverso la quale un malintenzionato cerca di ingannare la vittima convincendola a fornire informazioni personali, dati finanziari o codici di accesso, fingendosi un ente affidabile in una comunicazione digitale”)
– Social Network (“Sito Internet che fornisce agli utenti della rete un punto d’incontro virtuale per scambiarsi messaggi, chattare, condividere foto e video, ecc.”)
Voce Sintetizzata – Ho “clonato” la mia voce ed anche quella di una persona a caso…magari la tua?
Oggi ho fatto un esperimento per farmi un’idea di quanto sia complesso creare dei modelli sintetici della propria voce tramite i servizi di Intelligenza Artificiale e quanto questi possano essere accurati e fedeli.
Ottenere una voce non “robotica” che traduca il testo in suono (Il Text to Speech o anche conosciuto come TTS) è un lavoro che richiede oltre che competenze, anche del tempo. Partivo dunque con aspettative molto basse. Quello che più mi premeva verificare era la possibilità di sintetizzare la voce di qualcun altro, a sua insaputa. A quale scopo? Quello di fargli dire quello che voglio io, ma con la sua voce e senza che lui lo sappia (è un modo estremo per evidenziare un nuovo rischio derivato dal cattivo utilizzo dell’Intelligenza Artificiale).
Le premesse per realizzare un buon servizio di Text To Speech sono quelle di avere un training set adeguato, abbondante e di alta qualità. Alcuni esempi sono:
– Molte ore di registrazione (più di 8 ore per avere un qualcosa di decente)
– Nessun rumore di fondo
– Uniformità nel tono e nel ritmo della parlata per tutte le registrazioni
– Alta qualità della registrazione (no cuffiette o microfoni scadenti, ma un vero e proprio studio di registrazione)
– Un dizionario\lessico alquanto ampio con magari una focalizzazione sull’area di specializzazione del dispositivo (ad esempio in campo medico o meccatronico)
…
A quel punto, se dispongo di un software in grado di effettuare la sintetizzazione, basta dargli in pasto il training set, aspettare la magia ed ottimizzare il modello tramite la selezione di altri file audio, l’eliminazione di quelli che generano rumore, adeguare la velocità… ed altro ancora (salto tutto l’immenso lavoro che c’è in mezzo).
Quello qui sotto è ciò che ho ottenuto io con un training set davvero misero (20 registrazioni), effettuate con una cuffia e senza aver effettuato fine-tuning della mia soluzione. Nonostante abbia fatto del mio peggio, il mio timbro di voce è molto chiaro. Sono io, anche se parlo in maniera molto robotica.
Ecco il file audio prodotto (ripeto: 20 sample e non ho volutamente fatto ottimizzazioni di nessun tipo):
Tono e timbro della voce sono i miei! 😮
Ora viene il bello del mio esperimento: E se anziché sintetizzare la mia di voce, sintetizzassi quella di qualcun altro?
Chi non vorrebbe sentirsi dire dal proprio capo: “Ti do un bell’aumento!” oppure “Ti meriti una promozione e tre mesi di ferie pagate alle Hawaii”!?
Ho preso la palla al balzo e son andato a recuperare una vecchia registrazione di qualche minuto di una riunione fatta online con il mio capo. Ho frammentato il file per prendere solo le porzioni dove lui parlava, ne ho estratto il testo utilizzando un servizio di Speech Recognition, l’ho “ripulito, convertito, normalizzato…” e mi son così creato il mio training set anche se è molto lontano da essere utile a creare una voce realistica (solo 10 samples).
L’ho ad ogni modo dato in pasto alla piattaforma di sintetizzazione e….nel giro di poco tempo avevo il mio modello pronto per essere testato. Potevo farmi dire dal mio capo, quello che volevo!!!
Ecco il primo risultato che è chiaramente derivato da un training set “sporco” e poco utilizzabile:
Ora… il mio ha solo voluto essere un esperimento ed un gioco, ma se un domani venisse rilasciato uno strumento ad alta precisione che permettesse a chiunque di caricare una registrazione audio e generare dei modelli sintetizzati, la situazione potrebbe diventare poco piacevole. Così come potrebbe diventare molto utile per persone che vengono improvvisamente colpite da malattie che non permettono più loro di comunicare utilizzando la propria voce.
Siamo ancora lontani dallo scenario qui sopra (soprattutto per rendere la voce davvero naturale con un training set inappropriato), credo però che “la voce” sia un qualcosa che debba essere normata in qualche modo per evitare plagi.
Che io sappia, l’impronta Vocale è un qualcosa che ad oggi non è tutelata da norme di copyright. E’ forse il caso che si inizi a regolamentare anche questo aspetto per evitare spiacevoli attacchi di Phishing vocale e utilizzo improprio della tecnologia.
Quindi per il momento state tranquilli: non vi posso clonare…non ancora 🙂
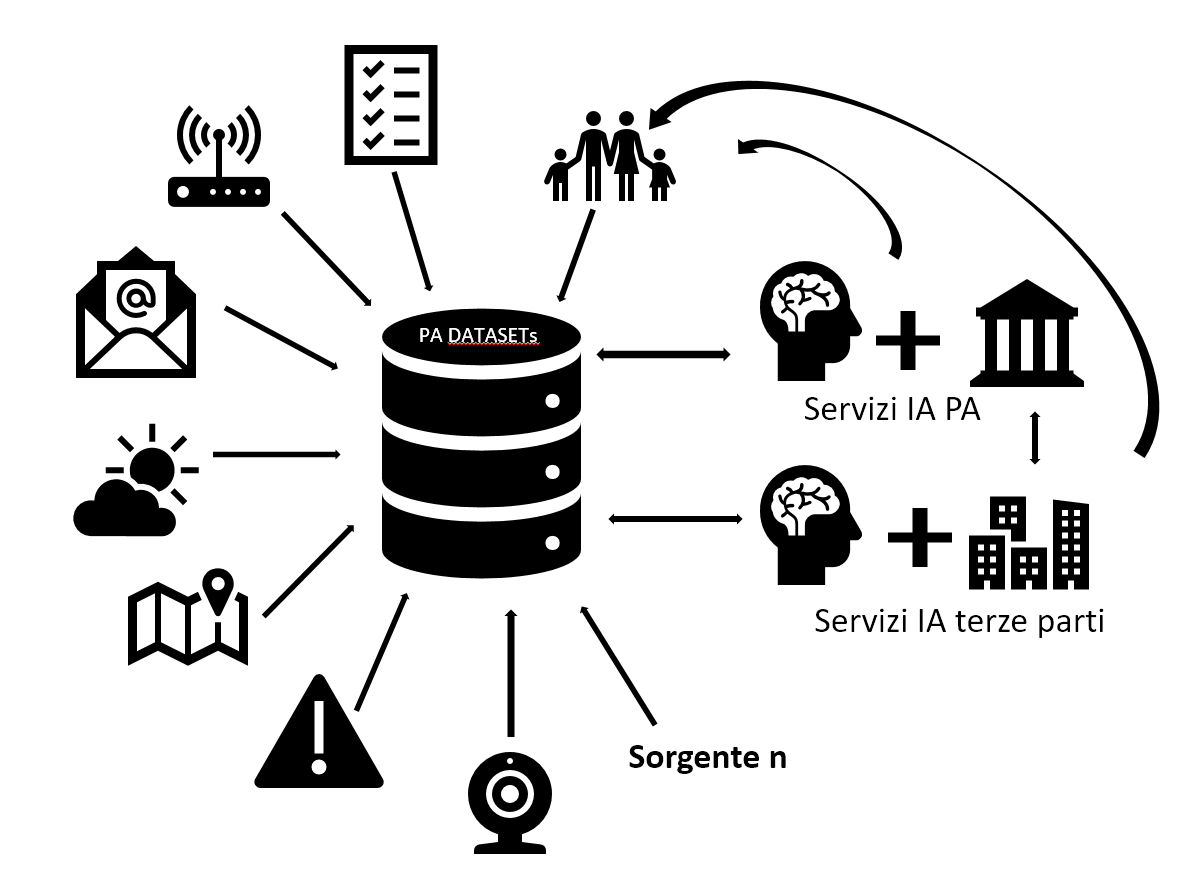
L’Intelligenza Artificiale per la Pubblica Amministrazione – “La PA come compagnia petrolifera del dato”
Ora che il White Paper “L’Intelligenza Artificiale al servizio del cittadino” al quale ho avuto il piacere e l’onore di contribuire è stato pubblicato, mi permetto di condividere uno dei miei contributi a cui tengo particolarmente e che per giuste necessità di sintesi, traspare solo parzialmente nel documento pubblicato e consultabile a questo link: https://ia.italia.it/assets/librobianco.pdf
La sfida in oggetto è quella dei DATI, che è un patrimonio che vorrei vedere sfruttato maggiormente per produrre nuovi servizi e risorse per le PMI, il cittadino e chiunque voglia partecipare all’ecosistema.
– – – – – – –
“La PA come compagnia petrolifera del dato” – I dati sono il petrolio dei giorni nostri e la PA siede su un giacimento parzialmente inesplorato ed inutilizzato che potrebbe generare un circolo virtuoso. Gli algoritmi di Machine Learning si basano e possono essere generati solo se si hanno a disposizione moli sufficienti di dati opportunamente organizzati e strutturati. Per dare un’idea, per effettuare il training di un modello efficiente in grado di riconoscere il parlato di una persona (Speech Recognition), Google ha utilizzato 50 Milioni di campioni come training set (Voice Samples)1. I dati a disposizione della PA possono provenire da fonti diverse come potrebbe essere un impianto elettrico, un sensore posizionato su un tombino, lo storico della manutenzione effettuata su una strada, il titolo o contenuto delle e-mail ricevute dai cittadini, un feed in tempo reale sulle previsioni meteo e così via. La PA ha l’opportunità di partecipare “all’economia del dato” oltre che generando servizi a valore aggiunto per il cittadino, anche creando un ecosistema che possa essere volano per le imprese del territorio interessate a generare servizi di Intelligenza Artificiale.
Alcuni dati, anche se in maniera minima e con un formato poco idoneo al Machine Learning sono ad oggi già a disposizione della PA (http://www.dati.gov.it/). Tuttavia, il processo d’immagazzinamento, organizzazione ed utilizzo necessita di una sostanziale revisione per poter diventare dataset utili allo sviluppo di servizi di Intelligenza Artificiale. Altri dati potrebbero essere invece derivati da quelli esistenti ed altri ancora potrebbero venire raccolti in base alle esigenze della PA e alle problematiche che si vogliono affrontare.
- Dati esistenti: Questi dati sono sparsi sul territorio e raccolti in formati diversi (inclusa l’archiviazione cartacea). Pensiamo a ciò che l’anagrafe ha a disposizione, alla mappatura degli impianti elettrici, alle informazioni provenienti dal catasto o a quelle ricavabili dalla manutenzione delle strade.
- Dati derivati: È possibile generare dati utili anche aggregando o eseguendo operazioni sui dati disponibili. In base al fine, si avranno una serie di elementi che possono generare un valore distribuibile per la PA
- Nuovi dati: Si tratta delle opportunità che l’IoT (Internet Of Things) ci offre. Pensiamo a sensori installabili sui margini dei corsi d’acqua, stream provenienti da videocamere, analytics provenienti dai siti web istituzionali consultati dai cittadini, dati acquisiti da terze parti e molto altro ancora
Tuttavia, ad oggi non esiste un sistema centralizzato adeguato per la raccolta\generazione e gestione del dato che permetterebbe di raggiungere la massa critica di informazioni necessarie per lo sviluppo (e l’ottimizzazione) di sistemi basati sul Machine Learning. Alcuni dei passi da esplorare sono quelli di:
- Centralizzare la raccolta del dato
- Consentire al cittadino di conoscere quali elementi vengono utilizzati e come
- Strutturare il formato del dato raccolto in base ai dataset che si vogliono generare
- Supervisionare il dato raccolto ed elaborato per evitare dataset sbilanciati (bias)
- Gestire l’accesso al dato
- Regolamentare l’utilizzo del dato
Nel pensare alla centralizzazione del dato, va ricordato che l’Italia si trova in una situazione di svantaggio rispetto ad altre nazioni in quella che è l’”Economia del dato”. È per questo che l’esigenza di accelerare la centralizzazione e la generazione di dati è uno degli elementi più pressanti da tenere in considerazione. Nazioni come Cina e Stati Uniti in primis dispongono di popolazioni più ampie e di conseguenza di possibilità di generare dataset maggiori. Lo stesso ragionamento si applica alla lingua parlata, dove sappiamo che l’Italiano è parlato da meno dell’1% della popolazione mondiale mentre la lingua cinese dal 14,1% e l’inglese dal 5,5% 2. Queste discrepanze possono creare gap quantitativi nella raccolta dei dati e qualitativi nello sviluppo di servizi di Intelligenza Artificiale.
Con opportuni investimenti, la PA può fornire un contributo concreto per rendere l’Italia un ecosistema competitivo sopperendo a carenze strutturali (vedasi popolazione e lingua), con processi avanzati atti alla generazione, raccolta ed utilizzo dei dati.
1 Fonte: Rishi Chandra – Vice President of Product Management and GM of Home Products Google
2 Lingue per numero di parlanti madrelingua
– – – – –
Il Libro Bianco pubblicato da AgID è solo l’inizio di un percorso e vuole essere uno stimolo per chi potrà e dovrà gestire l’integrazione e l’effetto che i servizi di AI avranno sul cittadino. La gestione dei dati è un’opportunità per la PA e per l’Italia, così come lo è la formazione del personale e dei lavoratori del futuro che avranno a che fare ogni giorno con i servizi di Intelligenza Artificiale.
Consiglio una lettura del testo integrale (una settantina di pagine, immagini incluse :)) e per chi volesse, è possibile partecipare alla discussione https://ia.italia.it/community/ e magari spingere affinché il governo realizzi l’opportunità dell’Ecosistema del dato 🙂
AI & Mr. Lee – Affrontare il cambiamento tecnologico e psicologico
Sono passati due anni (oggi) da quando AlphaGo ha battuto Mr. Lee, l’essere umano riconosciuto a livello internazionale come il super-campione di GO, un gioco così complesso da avere una combinazione di mosse\stati pari a 10 elevato alla 172 (lascio a voi i dettagli matematici). Lee ha vinto 18 titoli mondiali consecutivi ed in Corea del sud, è considerato un eroe nazionale.
L’espressione e lo stato d’animo di Lee in quel preciso momento in cui realizza che una macchina è stata migliore di lui sono illuminanti e mostrano quanto l’AI non vada solo affrontata a livello tecnologico ma anche sociale\psicologico:
– Si legge quanto la non conoscenza dell’AI possa sorprendere
– L’ego di un personaggio di 33 anni che non aveva ancora conosciuto grosse sconfitte, si ritrova improvvisamente schiacciato e Lee è privato di una sua certezza (non è più il migliore) e dotato di una nuova certezza (quella macchina sarà sempre più brava di lui).
A batterlo è stata una macchina che ha imparato “osservando” 160.000 partite giocate in giro per il mondo negli anni passati per un totale di 30.000.000 di mosse. Ma la cosa più sorprendente è che AlphaGo, ha imparato anche dall’unica sconfitta che Lee è riuscito ad infliggergli, senza dargli la possibilità di utilizzare nuovamente la stessa tattica per vincere le partite successive.
Una persona preparata su ciò che l’AI è in grado di fare e su come funziona, avrebbe accettato la sconfitta e apprezzato gli avanzamenti tecnologici. Se lo sarebbe aspettato e questo gli avrebbe permesso di superare il momento con un animo diverso.
A distanza di due anni abbiamo assistito a molti sviluppi dell’AI e alla demolizione di molte altre barriere. Qualcuno se ne è accorto mentre altri vivono ancora in un limbo che prima o poi li sorprenderà proprio così come han sorpreso Lee.
Mi piacerebbe che il prossimo Mr. Lee (che potrebbe essere banalmente una persona che si ritrova a guardare sbigottito il proprio telefonino, computer, autovettura, citofono…), fosse preparato ed in grado di comprendere le capacità dell’AI per poter affrontare il cambiamento tecnologico e psicologico in maniera appropriata.
Un cameriere dotato di Intelligenza Artificiale?
Oggi, a pranzo ho avuto modo di sperimentare con mano quanto lontani siamo ancora dal poter avere un’Intelligenza Artificiale che sia applicabile in campo ampio (Intelligenza Artificiale Generale)
Ero a Torino in un ristorante vicino a Porta Nuova e sono stato servito da due camerieri con tratti caratteristici complementari e parecchio differenti fra di essi. Uno era molto preciso, veloce ed efficiente, l’altra molto attenta alle esigenze dei clienti ed in grado di stabilire un rapporto emotivo.

Source: Serenityonlinetherapy.com
Ho provato a proiettare la situazione aggiungendo un terzo cameriere… “artificiale”.
Due sono state le situazioni che mi hanno colpito maggiormente e fatto pensare a quanto complesso sarebbe fare un training e creare dei dataset adeguati (per non parlare poi dell’ottimizzazione):
1- Quando ho chiesto indicazioni, alla cameriera che stava camminando per la sala con in mano tre piatti, per andare a servire un tavolo, questa si è fermata, ha spostato il terzo piatto sul braccio sul quale aveva gli altri due e con gesti cordiali mi ha indicato dove era il bagno con estrema precisione. In questo gesto non ci ho visto solo quello che in AI definiamo IQ, ma anche tanto EQ (Empatia). Ci ha tenuto ad indicarmi il posto per essere sicura che il messaggio arrivasse (ma forse son troppo ottimista ed ha solo pensato che io fossi rincoglionito…)
Immaginatevi di programmare un sistema di AI che deve servire ai tavoli. In questo caso probabilmente il cameriere-AI non si sarebbe fermato (lo scopo principale sarebbe stato quello di portare i piatti caldi al tavolo nel minor tempo possibile). Non avrebbe sentito l’esigenza di liberare la mano per gesticolare, il sorriso non sarebbe stato un atto dovuto e magari avrebbe comunicato la strada per andare al bagno con lo stesso volume con cui avrebbe letto il menu, anziché cercare un tono più discreto.
2 – Ad un certo punto del pranzo, il cameriere (un personaggio molto abile e veloce in sala – IQ), mi ha chiesto se potesse portare via il piatto, l’ho guardato e gli ho detto che avrei finito. Poi ho cercato di capire come mai il cameriere mi aveva fatto quella domanda. Ho osservato il piatto ed effettivamente al centro era vuoto, nella parte alta del piatto c’era la pelle dell’orata ed in basso a sinistra c’era un pezzo di carne di pesce con dei carciofi della stessa dimensione della pelle. Le posate erano messe allineate alle ore 4:20 (segnale che nel galateo indica che si ha finito). Inoltre, il bicchiere di vino era vuoto. Vi erano dei segnali che indicavano che:
– il piatto era vuoto se non per qualche scarto (anche se quello in basso non era uno scarto)
– la persona che stava mangiando aveva dato il segnale di fine con le posate (anche se involontariamente)
– a conferma, anche il bicchiere di vino che si era ordinato, era stato terminato… (messaggio che rinforza la fine del pasto)
In realtà le posate le avevo appoggiate senza troppo farci caso e per pura casualità, l’ultimo boccone restante non era in mezzo al piatto.
Ora, immaginatevi di dover dare delle indicazioni al cameriere-AI per poter prendere la giusta decisione:
- Di sicuro inserirei nel processo decisionale un segnale esplicito (il cameriere in effetti mi ha chiesto se poteva prendere il piatto…)
- Cercherei di fargli analizzare la posizione delle forchette (Il cameriere umano lo ha fatto)
- Guarderei il piatto per capire se c’è ancora del cibo (nel mio caso ce ne era poco e non nel centro, anche se era difficile da distinguere da ciò che avevo scartato)
Capite che se è difficile per l’uomo poter valutare correttamente tutti i segnali, per una macchina può essere ancora più complesso perché i segnali da interpretare possono essere “sporchi” (il mio piatto era vuoto o no? le posate erano state messe in quella posizione volutamente?). Il mio input vocale è stato “Ora finisco”, al quale è seguito un input visivo dove ho avvicinato la forchetta alla porzione del cibo rimasto in basso a sinistra indicando dove si trovava l’evidenza che indicava che non avevo ancora finito.
Quale feedback avrebbe ricevuto il cameriere-AI per migliorarsi la prossima volta?
In questo caso specifico, per poter gestire correttamente il secondo caso, il cameriere AI avrebbe dovuto essere un mix dei due camerieri e cercare un feedback esplicito in maniera diversa ed emotivamente più vicino a me (magari facendo una domanda meno diretta che però gli avrebbe permesso di capire che non avevo ancora finito), senza darmi l’impressione che qualcuno stava cercando di portarmi via il piatto).
Alla base però dell’errore del secondo cameriere, non c’è solo una carenza di EQ, ma anche e soprattutto il fatto che il mio input era fuorviante (BIAS). Ora, moltiplicate questa variabile per tutti gli esseri umani e vi accorgerete di quanto complessi siamo e di quanto è difficile generalizzare senza evitare bias.
Ad ogni modo, l’orata era deliziosa e con un sorriso ho ringraziato sia la cameriera che ha spostato il piatto per darmi indicazioni che il cameriere che nonostante quel malinteso, è stato efficiente.
Un Intelligenza Artificiale basata su reinforcement learning dovrebbe avere come compensazione\obbiettivo anche quello di ricevere sorrisi 😊
L’intelligenza Artificiale e la gestione del rischio
In questi giorni ho avuto modo di riflettere su quanto vasto sia l’impatto dei servizi di Intelligenza Artificiale e a come si stia affrontando la gestione del rischio e il testing.
Se pensiamo ad una macchina a guida autonoma gestita tramite dei servizi di Intelligenza Artificiale e ad un servizio di IA che aiuta un giudice a prendere una decisione in un procedimento penale, i fattori di rischio da gestire e le conseguenze di una decisione errata son bene diversi.
Si tratta sempre di servizi di Intelligenza Artificiale ma applicati a segmenti diversi.
Vi sono di sicuro degli elementi in comune in tutti i servizi di IA come lo sono i dati, gli algoritmi più o meno sofisticati e potenti macchine di calcolo.
Questi elementi espongono a rischi che devono essere affrontati e che ad oggi non siamo ancora in grado di gestire adeguatamente con le normative esistenti, i sistemi di testing e le linee guida relative all’etica (In fondo chi è in grado di definire che cosa è il giusto\buono per tutti?).
Se pensiamo alle automobili, ai frigoriferi, ai televisori e ad altri oggetti che vengono regolarmente immessi sul mercato, tutti questi devono rispettare determinate normative, spesso legate alle specifiche hardware\funzionali. In realtà già alcuni di questi oggetti hanno degli elementi di intelligenza che non sono regolamentati. Ad esempio, posso interagire con il mio TV (è solo un esempio perché vivo senza TV da parecchi anni 😊) parlandogli e ricevendo risposte, ma nessuno controlla se le risposte che il mio TV mi dà mi sta spingendo a commettere un crimine. Non esiste una normativa che tutela l’utente. Stessa cosa si applica per altri oggetti che integrano servizi di Intelligenza Artificiale e che non sono ancora regolamentati a dovere.

Sappiamo che il dato è alla base dei servizi di IA. Con esso però vi sono anche alcuni rischi associati:
- Bias
- Se il mio dataset non rappresenta un segmento aderente alla realtà e bilanciato, rischio di generare situazioni dove il mio servizio fornisce degli output che penalizzano una fascia della popolazione (vedi il caso della corte di giustizia americana che utilizzava l’IA per predire i casi di recidività e che incriminava con maggior frequenza gli Afro Americani o ancora il problema del Riconoscimento Vocale di Google che non era in grado di capire le donne con la stessa efficienza con cui capiva gli uomini)
- Se il trainingset (set di dati utilizzati per educare l’algoritmo) utilizzato non è stato giudicato correttamente (tagging), esiste il rischio che anche l’output sia “fuorviato” (Ad esempio se chiedo ad un suddito di Kim Jong Un di indicarmi in un dataset chi è buono e chi è cattivo in base alla nazionalità avrò probabilmente un giudizio diverso da quello dato da un fedele di Trump…)
- Il Machine Learning (l’apprendimento della macchina) prevede un continuo utilizzo dei nuovi dati per generare algoritmi sempre migliori. Alcuni servizi di Intelligenza Artificiale altamente personalizzati, potrebbero però cadere in un loop che distorce la realtà. Ne è un esempio il feed di Facebook che offre sempre più notizie con le quali si è interagito maggiormente o che sono rilevanti con il proprio network. A volte funziona bene mentre altre non proprio…In pratica se visualizzo e condivido alcuni video dei cinque stelle ed ho amici che fanno lo stesso oltre ad essere a loro volta amici di altri personaggi pro-movimento, rischio di trovarmi nel feed di Facebook notizie e commenti di un certo genere diventando parzialmente cieco verso quella che potrebbe essere la realtà
- Un bias può anche essere introdotto nell’algoritmo tramite dei dati farlocchi o un attacco di malintenzionati. Ne è un esempio quanto successo in passato con il Googlebombing dove un gruppo di persone ha creato dei link che partivano dai loro siti e puntavano alla biografia di Bush con il titolo “Miserable Failure”. Il risultato era che chi andava su Google e digitava la query “Miserable Failure”, si ritrovava fra i primi risultati la biografia di Bush.
Questi sono solo alcuni degli esempi di quanto l’Intelligenza Artificiale è ad oggi ancora troppo poco regolamentata e parzialmente “fragile”.
Sarebbe bene che si iniziassero a creare:
- Regolamentazioni adeguate e distinte per le varie categorie che impiegano ed impiegheranno servizi di IA (Trasporto, Elettrodomestici, Domotica, Applicazioni Aziendali…)
- Best Practise di Etica legate a che cosa è giusto insegnare alle macchine e come valutare correttamente un trainingset
- Un pool di esperti in ogni azienda che crea e fornisce servizi di Intelligenza Artificiale che sia responsabile di garantire determinate scelte etiche
- Le giuste competenze fra giuristi e legislatori per comprendere il funzionamento dei servizi di Intelligenza Artificiale e creare normative adeguate oltre che essere in grado di giudicare eventuali reati e responsabilità
Molto c’è ancora da fare, e come dicevo all’inizio dell’articolo, il campo è molto ampio. Da qualche parte bisognerà però pur iniziare 😊
Task Force Intelligenza Artificiale – Come partecipare
La scorsa settimana ho avuto il piacere di partecipare al kick-off della Task force di Intelligenza Artificiale promossa da AGID. Come dice il sito: “La task force si occupa di studiare come la diffusione di soluzioni e tecnologie di Intelligenza Artificiale (IA) possa incidere sull’evoluzione dei servizi pubblici per migliorare il rapporto tra pubblica amministrazione e cittadini.”
Al tavolo ed online, c’erano persone entusiaste che vivono l’AI dai suoi albori e persone che ne sono entrate in contatto più recentemente ma con un entusiasmo davvero importante.
Dopo gli eventi del week-end non si può non pensare a come l’AI può aiutare a prevenire e gestire situazioni difficili come straripamento di fiumi, bombe d’acqua o incendi. Cosa si sarebbe potuto fare se si fosse dato in pasto a dei servizi AI informazioni come:
- Stato di manutenzione dei corsi d’acqua (quando è stato dragato l’ultima volta?)
- Precipitazioni in tempo reale
- Insediamenti in aree a rischio inondazione
- Tipologia di terreno degli argini dei fiumi\rigagnoli
- Livello dei corsi d’acqua in tempo reale
- Etc…
Di sicuro non si sarebbe riusciti a fermare la pioggia, ma sarebbe stato possibile identificare aree che richiedevano manutenzione, persone da notificare in base alle precipitazioni ed all’altezza dei corsi d’acqua etc…
Sono queste alcune sfide che l’AI può aiutarci ad affrontare. Chiunque volesse contribuire al progetto di AGID, può dire la sua sul forum https://ia.italia.it/community/ appositamente creato per raccogliere idee ed informazioni utili.
Kena mobile recensione e opinioni (prova sul campo) – 2
Dopo varie settimane di utilizzo della SIM Kena Mobile posso completare la recensione sul suo funzionamento. Premetto che l’idea era quello di avere una SIM da utilizzare per il mio rilevatore GPS che mi permettesse di avere:
- Costi contenuti (ricordo a tutti che difficilmente si trovano piani tariffari che non includano SMS e Voce)
- Una buona copertura e continuità di servizio
- Un discreto volume di traffico internet a qualsiasi velocità di connessione
Analizzerò ogni voce sopra elencata premettendo che per capire come si comportava la SIM, l’ho utilizzata sul mio telefono Android prima (LG Nexus) e su un rilevatore GPS che precedentemente usavo con una SIM 3 (Si tratta di un TK907).
Kena Mobile e i costi contenuti
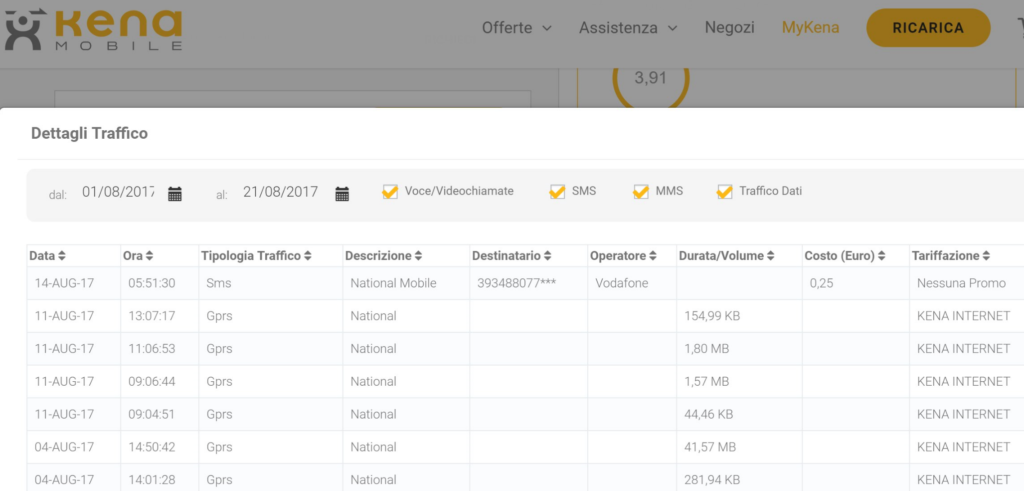
La promessa è stata mantenuta. Sto pagando 4€ al mese. Ovviamente per chi è abituato al 4G, navigare a 3G potrebbe essere un limite (soprattutto per chi utilizza servizi di streaming), ma per il resto, non ho avuto costi aggiuntivi a parte un SMS mandato dall’estero con vari problemi che a breve racconterò. Per comodità e per agganciarmi all’argomento successivo metto qui sotto un’immagine del mio traffico e dei costi. Ovviamente, come avevo ipotizzato precedentemente per visualizzare questa pagina, ho dovuto ri-registrarmi al sito di Kena Mobile con il numero di telefono mantenuto grazie alla portabilità.
Come si vede i costi sono zero tranne che per il 14 Agosto. In quella data ho mandato un SMS dalla Grecia.
Si nota anche che c’è stato un black-out fra l’11 e il 14. In realtà in quel periodo ero in Grecia ed il telefono si è magicamente trasformato in un “feature phone”. Ovvero, Kena Mobile, dall’estero anche all’interno della comunità Europea, non funziona per il traffico dati. Potevo solo fare telefonate e mandare SMS.
Una buona copertura
Questa forse è la nota dolente. I primi giorni di utilizzo, non so se per via della portabilità, ho sofferto abbastanza. Spesso ricevevo messaggi del tipo “Nessun segnale” o “Problemi di autenticazione rete”, quando in realtà con un altro telefono con la SIM TIM, avevo connettività senza problemi (ero a Milano quando ricevevo questi messaggi in punti dove fino a pochi minuti prima tutto funzionava a dovere). Questi malfunzionamenti son andati avanti per 3-4 giorni. La situazione si è poi stabilizzata e a parte quando sono andato in Grecia, non ho più avuto difficoltà con la SIM Kena mobile a connettermi ad Internet. Ecco alcune immagini dei messaggi di errore ricevuti. Come dicevo, a parte la prima fase, la SIM Kena non ha poi dato problemi di connettività Internet in Italia.
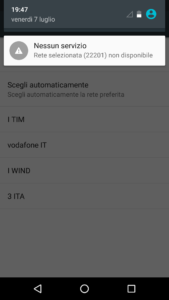
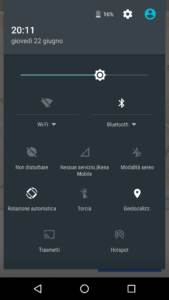
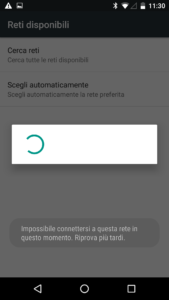
Per quanto riguarda l’estero, sono andato a rileggermi il contratto e l’offerta. Alla pagina https://www.kenamobile.it/prodotto/kena-internet/ noto che la SIM Kena dovrebbe in teoria funzionare anche all’estero.

Non è stato il mio caso. Essendo però inserita sul mio telefono secondario, son riuscito a sopravvivere al problema, ma immagino quanto frustrante possa essere l’esperienza per chi usa la SIM Kena sul suo telefono principale (se non l’unico).
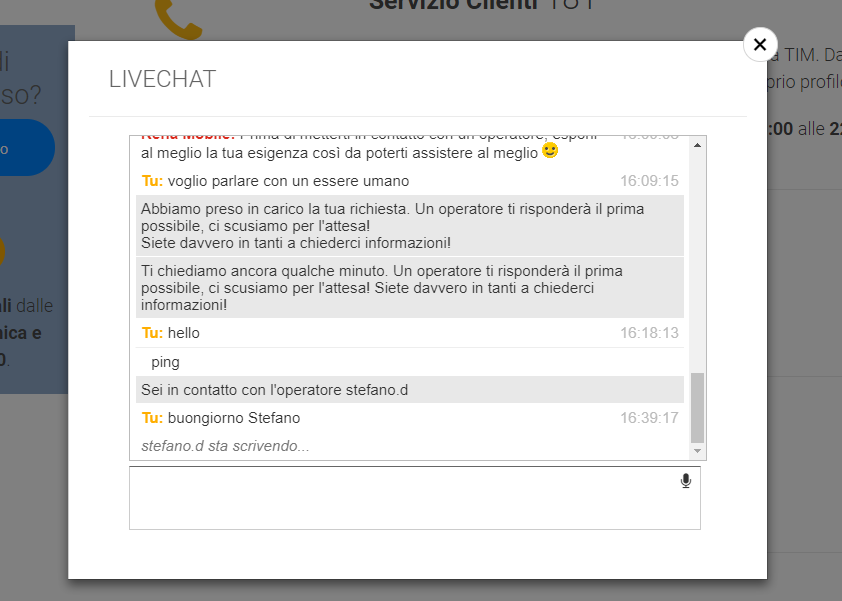
Giusto per essere sicuro, ho contattato il servizio clienti per verificare. Alle 10 di mattina ho inviato tramite il sito www.kenamobile.it una richiesta per essere ricontattato. Alle 16 (6 ore dopo) nessuno mi aveva ancora contattato ed ho quindi optato per parlare con il servizio via Chat. Premetto che lavoro nell’ambiente dei Bot\Digital Assistant e che son in grado di riconoscere i “risponditori automatici” e di sapere come forzare alcune risposte\scenari. Ovviamente a rispondermi è stato un Bot che faceva ampio filtro rendendo il contatto con un essere umano difficile (Kena Mobile come altri, utilizza questo stratagemma per abbassare i costi – nulla da dire). Quello sul quale invece si può recriminare sono i tempi di attesa per far sì che un essere umano rispondesse alla chiamata veicolata tramite il Bot. Ho dovuto digitare due volte la frase “Voglio parlare con un essere umano” per bypassare il filtro e far capire al Bot che era il caso di deviare la conversazione. Come si evince dall’immagine qui sotto, sono un uomo paziente: Ho aspettato 30 minuti per parlare con un operatore del servizio clienti di Kena Mobile!!! 30 minuti non sono giustificabili così come non lo sono le 6 ore di attesa per essere ricontattato telefonicamente (sto ancora aspettando adesso in realtà).
In tutto questo il risponditore automatico mi ha dato un’utile indicazione: il fatto che la SIM Kena mobile nuova o inserita in un nuovo dispositivo, faccia fatica ad agganciarsi alla rete, è un fatto conosciuto.
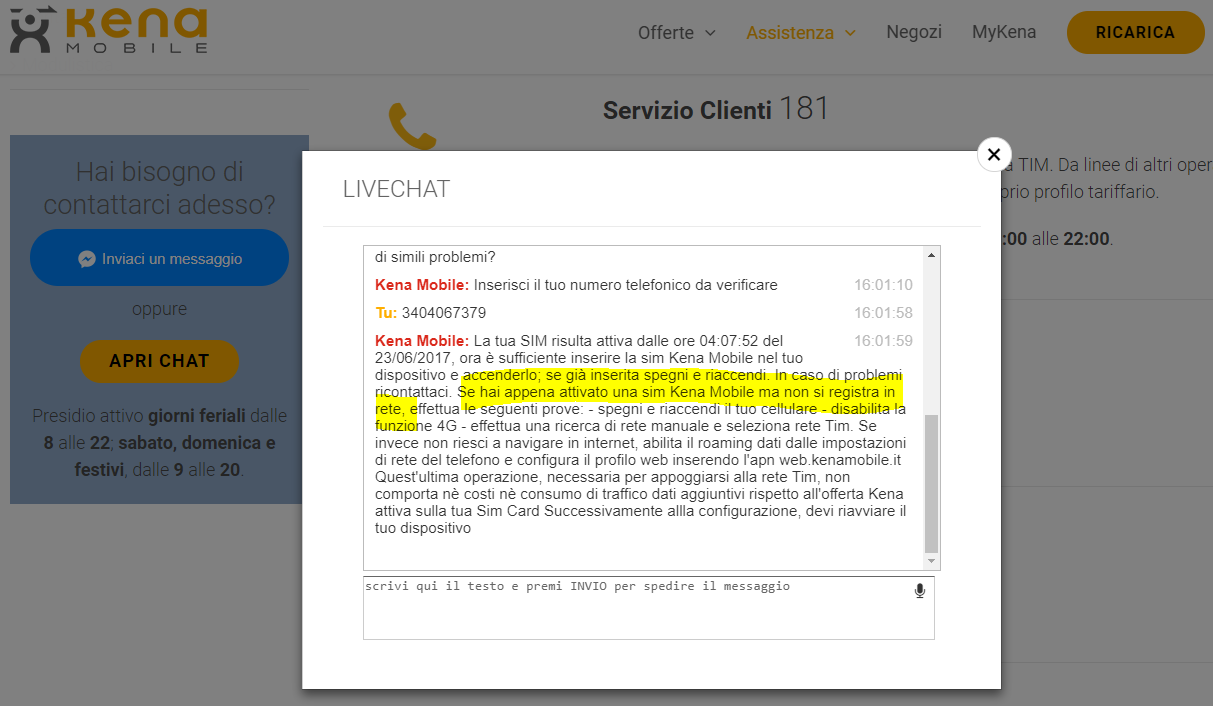
Invece ciò che l’operatore del servizio clienti ha condiviso con me è stato meno utile:
- Non è stato in grado di dirmi se il problema di connessione alla rete internet dall’estero con la SIM Kena è un problema noto, sostenendo il fatto che ormai ero in Italia e non era possibile fare un debugging. Ottima scusa, ma tutti i customer center che si rispettino hanno un Knowledge Base nel quale verificare le istanze di un dato avvenimento. L’operatore non si è degnato di verificare…o forse il sistema che utilizza non è in grado di dare un simile riscontro, il che sarebbe ancora peggio
- Giusto per verificare la qualità del servizio, chiedo se la SIM che supporta 3G in realtà funziona anche su oggetti IoT che magari utilizzano GPRS o connessioni diverse ma sempre dello standard GSM. Mi è stato risposto che la SIM Kena mobile garantisce il funzionamento solo sui telefoni. Trovo la risposta alquanto bizzarra e poco utile.
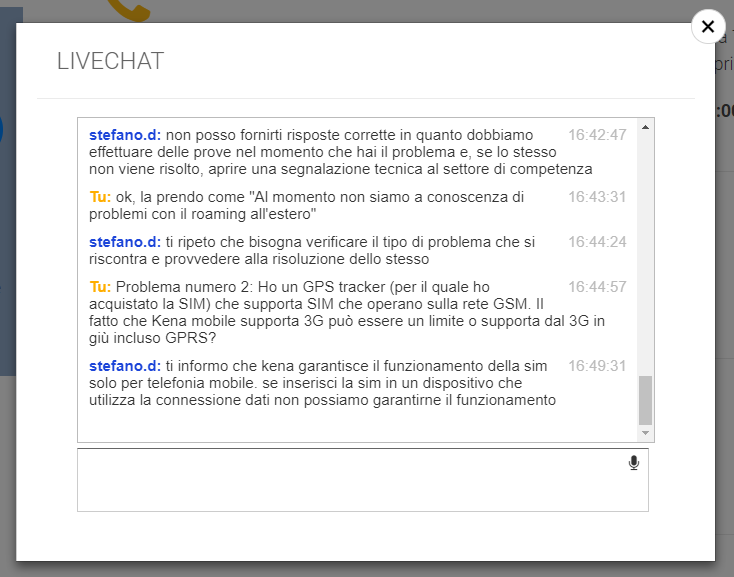
Visto che il mio obbiettivo era usare la SIM su un rilevatore GPS, ovviamente la risposta mi fa allarmare. Il modo migliore per verificare è quello di provare ad inserire la SIM Kena sul mio oggetto IoT.
Un discreto volume di traffico internet a qualsiasi velocità di connessione
Dopo essermi accertato che con la scheda 3 tutto funzioni a dovere, procedo sostituendo la scheda 3 con la mia scheda Kena Mobile. Noto subito che gli indicatori luminosi anziché spegnersi ed accendersi, restano costantemente accesi. Brutto segno ma non dispero. Provo a rimuovere la SIM, resettare il rilevatore GPS e reinserire la SIM. Stesso scenario. Non funziona. Rimetto la scheda 3 e tutto va come dovrebbe andare. Reinserisco la scheda Kena, riavvio il device ma nulla cambia. Provo a telefonare al mio numero Kena tramite un altro telefono e mi dice che il numero non è raggiungibile. A questo punto inizio a credere all’operatore di Kena che mi aveva detto che non vi sono garanzie sul funzionamento della scheda Kena, all’interno di oggetti diversi da un telefono. Al punto 3 quindi non sono ancora in grado di rispondere. Lato telefono, posso dire che a parte una fase iniziale e il periodo all’estero, il piano tariffario Internet di Kena mobile si è dimostrato valido.
Lato IoT, se come suppongo i problemi che sto riscontrando sono legati alla difficoltà della SIM di agganciarsi alla rete, la situazione diventa difficile. Con un device headless come il mio rilevatore GPS, non posso forzare la selezione della rete alla quale agganciarsi.
In sintesi posso dire che non mi ritengo soddisfatto completamente del passaggio a Kena Mobile perché:
- A me serviva principalmente per il rilevatore GPS e ad oggi non sono riuscito ancora a fare andare la scheda sul mio oggetto IoT
- Il customer support di Kena Mobile è scadente con lunghi tempi di attesa e poche risposte utili
- Per mia personale eperienza (che non è detto che sia poi quella di tutti), all’estero la scheda Kena Mobile non funzionava per la parte di connessione Internet
Cosa c’è dietro ai bot di Facebook che inventano un loro linguaggio
Avrete sicuramente letto recentemente degli articoli relativi ad un esperimento di Facebook conclusosi in maniera anomala dove due bot (si tratta di programmi intelligenti in grado di sostenere conversazioni in linguaggio naturale) erano stati incaricati di parlare fra di loro, con l’obbiettivo di svolgere una trattativa.
Oggi un collega (Andrea Benedetti che ringrazio) mi ha ricordato la vicenda evidenziando un elemento interessante in merito a quanto realmente successo. L’esperimento è stato terminato non perché era sfuggito di mano così come i vari media han raccontato inizialmente, ma perché in realtà l’output delle conversazioni era uscito dal campo di sperimentazione e risultava inutile (i bot non utilizzavano più un linguaggio a noi comprensibile).
Cosa sia successo lo spiega molto bene in questo breve video David Puente
Quello che vedo io, in realtà è un qualcosa di ancora più interessante che dovrebbe far riflettere su quanto è importante definire dei design principle e delle chiare linee guida.
Così come con Tay, Microsoft non aveva impostato alcuni paletti per determinati argomenti sensibili che dovevano essere moderati, i Bot di Messenger non hanno avuto linee guida in merito al linguaggio che dovevano utilizzare. Per gestire la trattativa i bot hanno così creato dei loro codici linguistici che avrebbero dovuto “deviare” la conversazione a loro favore. Interessante vedere come sia bastata una sola stringa con il nuovo modello “conversazionale” (la nuova lingua creata da uno dei due bot) per deviare completamente tutta la conversazione.
Per le logiche del Machine Learning, quella stringa è entrata a far parte del training set (la base di dati utilizzata per educare il modello), deviando quindi il risultato finale. Come in ogni progetto, anche per l’intelligenza artificiale è importante definire bene sin dall’inizio i paletti ed i rischi per evitare di dover poi fare delle correzioni in corso.