Voce Sintetizzata – Ho “clonato” la mia voce ed anche quella di una persona a caso…magari la tua?
Oggi ho fatto un esperimento per farmi un’idea di quanto sia complesso creare dei modelli sintetici della propria voce tramite i servizi di Intelligenza Artificiale e quanto questi possano essere accurati e fedeli.
Ottenere una voce non “robotica” che traduca il testo in suono (Il Text to Speech o anche conosciuto come TTS) è un lavoro che richiede oltre che competenze, anche del tempo. Partivo dunque con aspettative molto basse. Quello che più mi premeva verificare era la possibilità di sintetizzare la voce di qualcun altro, a sua insaputa. A quale scopo? Quello di fargli dire quello che voglio io, ma con la sua voce e senza che lui lo sappia (è un modo estremo per evidenziare un nuovo rischio derivato dal cattivo utilizzo dell’Intelligenza Artificiale).
Le premesse per realizzare un buon servizio di Text To Speech sono quelle di avere un training set adeguato, abbondante e di alta qualità. Alcuni esempi sono:
– Molte ore di registrazione (più di 8 ore per avere un qualcosa di decente)
– Nessun rumore di fondo
– Uniformità nel tono e nel ritmo della parlata per tutte le registrazioni
– Alta qualità della registrazione (no cuffiette o microfoni scadenti, ma un vero e proprio studio di registrazione)
– Un dizionario\lessico alquanto ampio con magari una focalizzazione sull’area di specializzazione del dispositivo (ad esempio in campo medico o meccatronico)
…
A quel punto, se dispongo di un software in grado di effettuare la sintetizzazione, basta dargli in pasto il training set, aspettare la magia ed ottimizzare il modello tramite la selezione di altri file audio, l’eliminazione di quelli che generano rumore, adeguare la velocità… ed altro ancora (salto tutto l’immenso lavoro che c’è in mezzo).
Quello qui sotto è ciò che ho ottenuto io con un training set davvero misero (20 registrazioni), effettuate con una cuffia e senza aver effettuato fine-tuning della mia soluzione. Nonostante abbia fatto del mio peggio, il mio timbro di voce è molto chiaro. Sono io, anche se parlo in maniera molto robotica.
Ecco il file audio prodotto (ripeto: 20 sample e non ho volutamente fatto ottimizzazioni di nessun tipo):
Tono e timbro della voce sono i miei! 😮
Ora viene il bello del mio esperimento: E se anziché sintetizzare la mia di voce, sintetizzassi quella di qualcun altro?
Chi non vorrebbe sentirsi dire dal proprio capo: “Ti do un bell’aumento!” oppure “Ti meriti una promozione e tre mesi di ferie pagate alle Hawaii”!?
Ho preso la palla al balzo e son andato a recuperare una vecchia registrazione di qualche minuto di una riunione fatta online con il mio capo. Ho frammentato il file per prendere solo le porzioni dove lui parlava, ne ho estratto il testo utilizzando un servizio di Speech Recognition, l’ho “ripulito, convertito, normalizzato…” e mi son così creato il mio training set anche se è molto lontano da essere utile a creare una voce realistica (solo 10 samples).
L’ho ad ogni modo dato in pasto alla piattaforma di sintetizzazione e….nel giro di poco tempo avevo il mio modello pronto per essere testato. Potevo farmi dire dal mio capo, quello che volevo!!!
Ecco il primo risultato che è chiaramente derivato da un training set “sporco” e poco utilizzabile:
Ora… il mio ha solo voluto essere un esperimento ed un gioco, ma se un domani venisse rilasciato uno strumento ad alta precisione che permettesse a chiunque di caricare una registrazione audio e generare dei modelli sintetizzati, la situazione potrebbe diventare poco piacevole. Così come potrebbe diventare molto utile per persone che vengono improvvisamente colpite da malattie che non permettono più loro di comunicare utilizzando la propria voce.
Siamo ancora lontani dallo scenario qui sopra (soprattutto per rendere la voce davvero naturale con un training set inappropriato), credo però che “la voce” sia un qualcosa che debba essere normata in qualche modo per evitare plagi.
Che io sappia, l’impronta Vocale è un qualcosa che ad oggi non è tutelata da norme di copyright. E’ forse il caso che si inizi a regolamentare anche questo aspetto per evitare spiacevoli attacchi di Phishing vocale e utilizzo improprio della tecnologia.
Quindi per il momento state tranquilli: non vi posso clonare…non ancora 🙂
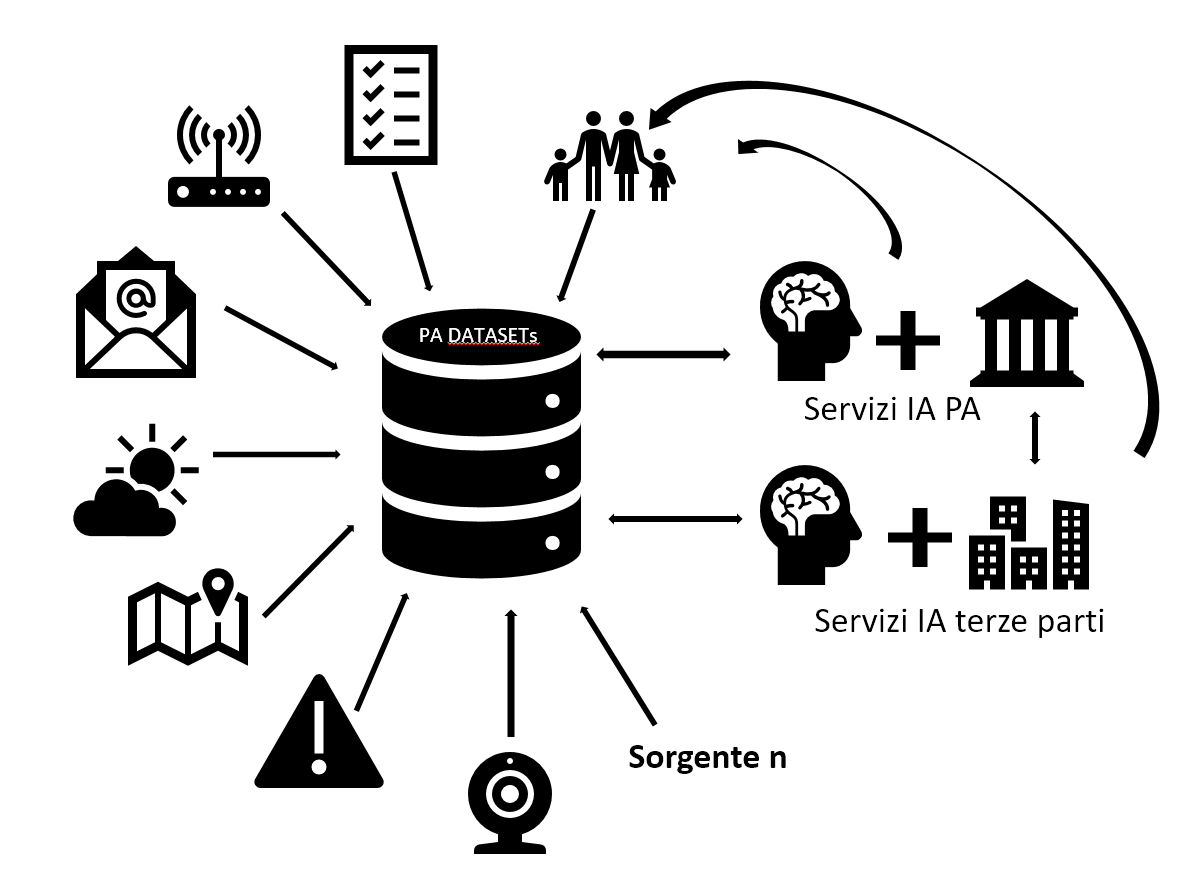
L’Intelligenza Artificiale per la Pubblica Amministrazione – “La PA come compagnia petrolifera del dato”
Ora che il White Paper “L’Intelligenza Artificiale al servizio del cittadino” al quale ho avuto il piacere e l’onore di contribuire è stato pubblicato, mi permetto di condividere uno dei miei contributi a cui tengo particolarmente e che per giuste necessità di sintesi, traspare solo parzialmente nel documento pubblicato e consultabile a questo link: https://ia.italia.it/assets/librobianco.pdf
La sfida in oggetto è quella dei DATI, che è un patrimonio che vorrei vedere sfruttato maggiormente per produrre nuovi servizi e risorse per le PMI, il cittadino e chiunque voglia partecipare all’ecosistema.
– – – – – – –
“La PA come compagnia petrolifera del dato” – I dati sono il petrolio dei giorni nostri e la PA siede su un giacimento parzialmente inesplorato ed inutilizzato che potrebbe generare un circolo virtuoso. Gli algoritmi di Machine Learning si basano e possono essere generati solo se si hanno a disposizione moli sufficienti di dati opportunamente organizzati e strutturati. Per dare un’idea, per effettuare il training di un modello efficiente in grado di riconoscere il parlato di una persona (Speech Recognition), Google ha utilizzato 50 Milioni di campioni come training set (Voice Samples)1. I dati a disposizione della PA possono provenire da fonti diverse come potrebbe essere un impianto elettrico, un sensore posizionato su un tombino, lo storico della manutenzione effettuata su una strada, il titolo o contenuto delle e-mail ricevute dai cittadini, un feed in tempo reale sulle previsioni meteo e così via. La PA ha l’opportunità di partecipare “all’economia del dato” oltre che generando servizi a valore aggiunto per il cittadino, anche creando un ecosistema che possa essere volano per le imprese del territorio interessate a generare servizi di Intelligenza Artificiale.
Alcuni dati, anche se in maniera minima e con un formato poco idoneo al Machine Learning sono ad oggi già a disposizione della PA (http://www.dati.gov.it/). Tuttavia, il processo d’immagazzinamento, organizzazione ed utilizzo necessita di una sostanziale revisione per poter diventare dataset utili allo sviluppo di servizi di Intelligenza Artificiale. Altri dati potrebbero essere invece derivati da quelli esistenti ed altri ancora potrebbero venire raccolti in base alle esigenze della PA e alle problematiche che si vogliono affrontare.
- Dati esistenti: Questi dati sono sparsi sul territorio e raccolti in formati diversi (inclusa l’archiviazione cartacea). Pensiamo a ciò che l’anagrafe ha a disposizione, alla mappatura degli impianti elettrici, alle informazioni provenienti dal catasto o a quelle ricavabili dalla manutenzione delle strade.
- Dati derivati: È possibile generare dati utili anche aggregando o eseguendo operazioni sui dati disponibili. In base al fine, si avranno una serie di elementi che possono generare un valore distribuibile per la PA
- Nuovi dati: Si tratta delle opportunità che l’IoT (Internet Of Things) ci offre. Pensiamo a sensori installabili sui margini dei corsi d’acqua, stream provenienti da videocamere, analytics provenienti dai siti web istituzionali consultati dai cittadini, dati acquisiti da terze parti e molto altro ancora
Tuttavia, ad oggi non esiste un sistema centralizzato adeguato per la raccolta\generazione e gestione del dato che permetterebbe di raggiungere la massa critica di informazioni necessarie per lo sviluppo (e l’ottimizzazione) di sistemi basati sul Machine Learning. Alcuni dei passi da esplorare sono quelli di:
- Centralizzare la raccolta del dato
- Consentire al cittadino di conoscere quali elementi vengono utilizzati e come
- Strutturare il formato del dato raccolto in base ai dataset che si vogliono generare
- Supervisionare il dato raccolto ed elaborato per evitare dataset sbilanciati (bias)
- Gestire l’accesso al dato
- Regolamentare l’utilizzo del dato
Nel pensare alla centralizzazione del dato, va ricordato che l’Italia si trova in una situazione di svantaggio rispetto ad altre nazioni in quella che è l’”Economia del dato”. È per questo che l’esigenza di accelerare la centralizzazione e la generazione di dati è uno degli elementi più pressanti da tenere in considerazione. Nazioni come Cina e Stati Uniti in primis dispongono di popolazioni più ampie e di conseguenza di possibilità di generare dataset maggiori. Lo stesso ragionamento si applica alla lingua parlata, dove sappiamo che l’Italiano è parlato da meno dell’1% della popolazione mondiale mentre la lingua cinese dal 14,1% e l’inglese dal 5,5% 2. Queste discrepanze possono creare gap quantitativi nella raccolta dei dati e qualitativi nello sviluppo di servizi di Intelligenza Artificiale.
Con opportuni investimenti, la PA può fornire un contributo concreto per rendere l’Italia un ecosistema competitivo sopperendo a carenze strutturali (vedasi popolazione e lingua), con processi avanzati atti alla generazione, raccolta ed utilizzo dei dati.
1 Fonte: Rishi Chandra – Vice President of Product Management and GM of Home Products Google
2 Lingue per numero di parlanti madrelingua
– – – – –
Il Libro Bianco pubblicato da AgID è solo l’inizio di un percorso e vuole essere uno stimolo per chi potrà e dovrà gestire l’integrazione e l’effetto che i servizi di AI avranno sul cittadino. La gestione dei dati è un’opportunità per la PA e per l’Italia, così come lo è la formazione del personale e dei lavoratori del futuro che avranno a che fare ogni giorno con i servizi di Intelligenza Artificiale.
Consiglio una lettura del testo integrale (una settantina di pagine, immagini incluse :)) e per chi volesse, è possibile partecipare alla discussione https://ia.italia.it/community/ e magari spingere affinché il governo realizzi l’opportunità dell’Ecosistema del dato 🙂
L’intelligenza Artificiale e la gestione del rischio
In questi giorni ho avuto modo di riflettere su quanto vasto sia l’impatto dei servizi di Intelligenza Artificiale e a come si stia affrontando la gestione del rischio e il testing.
Se pensiamo ad una macchina a guida autonoma gestita tramite dei servizi di Intelligenza Artificiale e ad un servizio di IA che aiuta un giudice a prendere una decisione in un procedimento penale, i fattori di rischio da gestire e le conseguenze di una decisione errata son bene diversi.
Si tratta sempre di servizi di Intelligenza Artificiale ma applicati a segmenti diversi.
Vi sono di sicuro degli elementi in comune in tutti i servizi di IA come lo sono i dati, gli algoritmi più o meno sofisticati e potenti macchine di calcolo.
Questi elementi espongono a rischi che devono essere affrontati e che ad oggi non siamo ancora in grado di gestire adeguatamente con le normative esistenti, i sistemi di testing e le linee guida relative all’etica (In fondo chi è in grado di definire che cosa è il giusto\buono per tutti?).
Se pensiamo alle automobili, ai frigoriferi, ai televisori e ad altri oggetti che vengono regolarmente immessi sul mercato, tutti questi devono rispettare determinate normative, spesso legate alle specifiche hardware\funzionali. In realtà già alcuni di questi oggetti hanno degli elementi di intelligenza che non sono regolamentati. Ad esempio, posso interagire con il mio TV (è solo un esempio perché vivo senza TV da parecchi anni 😊) parlandogli e ricevendo risposte, ma nessuno controlla se le risposte che il mio TV mi dà mi sta spingendo a commettere un crimine. Non esiste una normativa che tutela l’utente. Stessa cosa si applica per altri oggetti che integrano servizi di Intelligenza Artificiale e che non sono ancora regolamentati a dovere.

Sappiamo che il dato è alla base dei servizi di IA. Con esso però vi sono anche alcuni rischi associati:
- Bias
- Se il mio dataset non rappresenta un segmento aderente alla realtà e bilanciato, rischio di generare situazioni dove il mio servizio fornisce degli output che penalizzano una fascia della popolazione (vedi il caso della corte di giustizia americana che utilizzava l’IA per predire i casi di recidività e che incriminava con maggior frequenza gli Afro Americani o ancora il problema del Riconoscimento Vocale di Google che non era in grado di capire le donne con la stessa efficienza con cui capiva gli uomini)
- Se il trainingset (set di dati utilizzati per educare l’algoritmo) utilizzato non è stato giudicato correttamente (tagging), esiste il rischio che anche l’output sia “fuorviato” (Ad esempio se chiedo ad un suddito di Kim Jong Un di indicarmi in un dataset chi è buono e chi è cattivo in base alla nazionalità avrò probabilmente un giudizio diverso da quello dato da un fedele di Trump…)
- Il Machine Learning (l’apprendimento della macchina) prevede un continuo utilizzo dei nuovi dati per generare algoritmi sempre migliori. Alcuni servizi di Intelligenza Artificiale altamente personalizzati, potrebbero però cadere in un loop che distorce la realtà. Ne è un esempio il feed di Facebook che offre sempre più notizie con le quali si è interagito maggiormente o che sono rilevanti con il proprio network. A volte funziona bene mentre altre non proprio…In pratica se visualizzo e condivido alcuni video dei cinque stelle ed ho amici che fanno lo stesso oltre ad essere a loro volta amici di altri personaggi pro-movimento, rischio di trovarmi nel feed di Facebook notizie e commenti di un certo genere diventando parzialmente cieco verso quella che potrebbe essere la realtà
- Un bias può anche essere introdotto nell’algoritmo tramite dei dati farlocchi o un attacco di malintenzionati. Ne è un esempio quanto successo in passato con il Googlebombing dove un gruppo di persone ha creato dei link che partivano dai loro siti e puntavano alla biografia di Bush con il titolo “Miserable Failure”. Il risultato era che chi andava su Google e digitava la query “Miserable Failure”, si ritrovava fra i primi risultati la biografia di Bush.
Questi sono solo alcuni degli esempi di quanto l’Intelligenza Artificiale è ad oggi ancora troppo poco regolamentata e parzialmente “fragile”.
Sarebbe bene che si iniziassero a creare:
- Regolamentazioni adeguate e distinte per le varie categorie che impiegano ed impiegheranno servizi di IA (Trasporto, Elettrodomestici, Domotica, Applicazioni Aziendali…)
- Best Practise di Etica legate a che cosa è giusto insegnare alle macchine e come valutare correttamente un trainingset
- Un pool di esperti in ogni azienda che crea e fornisce servizi di Intelligenza Artificiale che sia responsabile di garantire determinate scelte etiche
- Le giuste competenze fra giuristi e legislatori per comprendere il funzionamento dei servizi di Intelligenza Artificiale e creare normative adeguate oltre che essere in grado di giudicare eventuali reati e responsabilità
Molto c’è ancora da fare, e come dicevo all’inizio dell’articolo, il campo è molto ampio. Da qualche parte bisognerà però pur iniziare 😊
Task Force Intelligenza Artificiale – Come partecipare
La scorsa settimana ho avuto il piacere di partecipare al kick-off della Task force di Intelligenza Artificiale promossa da AGID. Come dice il sito: “La task force si occupa di studiare come la diffusione di soluzioni e tecnologie di Intelligenza Artificiale (IA) possa incidere sull’evoluzione dei servizi pubblici per migliorare il rapporto tra pubblica amministrazione e cittadini.”
Al tavolo ed online, c’erano persone entusiaste che vivono l’AI dai suoi albori e persone che ne sono entrate in contatto più recentemente ma con un entusiasmo davvero importante.
Dopo gli eventi del week-end non si può non pensare a come l’AI può aiutare a prevenire e gestire situazioni difficili come straripamento di fiumi, bombe d’acqua o incendi. Cosa si sarebbe potuto fare se si fosse dato in pasto a dei servizi AI informazioni come:
- Stato di manutenzione dei corsi d’acqua (quando è stato dragato l’ultima volta?)
- Precipitazioni in tempo reale
- Insediamenti in aree a rischio inondazione
- Tipologia di terreno degli argini dei fiumi\rigagnoli
- Livello dei corsi d’acqua in tempo reale
- Etc…
Di sicuro non si sarebbe riusciti a fermare la pioggia, ma sarebbe stato possibile identificare aree che richiedevano manutenzione, persone da notificare in base alle precipitazioni ed all’altezza dei corsi d’acqua etc…
Sono queste alcune sfide che l’AI può aiutarci ad affrontare. Chiunque volesse contribuire al progetto di AGID, può dire la sua sul forum https://ia.italia.it/community/ appositamente creato per raccogliere idee ed informazioni utili.